WAN 2.1 I2V Native Workflow [8GB VRAM]
Requirements
- Minimum Hardware: 8GB VRAM and 16GB RAM (Tested with an RTX 3070 8GB)
Also you'll need GGUF version of WAN Video model,
Download wan2.1-i2v-14b-720p-Q4_K_S model from here : https://huggingface.co/city96/Wan2.1-I2V-14B-720P-gguf/tree/main
Sage Attention 2
You'll need Git, Install Git using this link : https://git-scm.com/
The guide to install Sage Attention 1 is include in my previous Hunyuan Video T2V Native workflow post: https://brewni.com/Genai/ULNks9g1?tag=0
You have to follow these, otherwise Triton won't work
If you followed the guide, open terminal in your comfyui folder and type this,
git clone https://github.com/thu-ml/SageAttention.git
if you already installed sageattention 1, type this,
.\python_embeded\python.exe -m pip uninstall sageattention
Open SageAttention folder, Open terminal inside SageAttention folder and type this,
..\python_embeded\python.exe -m pip install -e .
--Fast Arg
the '--fast' arg will reduce your generation time about 20%, but you need to install nightly version of Pytorch
Please use caution when installing the nightly version of Pytorch, as some custom nodes may not work.
open terminal in your comfyui folder and type this,
.\python_embeded\python.exe -m pip install --upgrade --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
Edit your run_nvidia_gpu.bat with notepad, like this
.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build --use-sage-attention --fast
Workflow
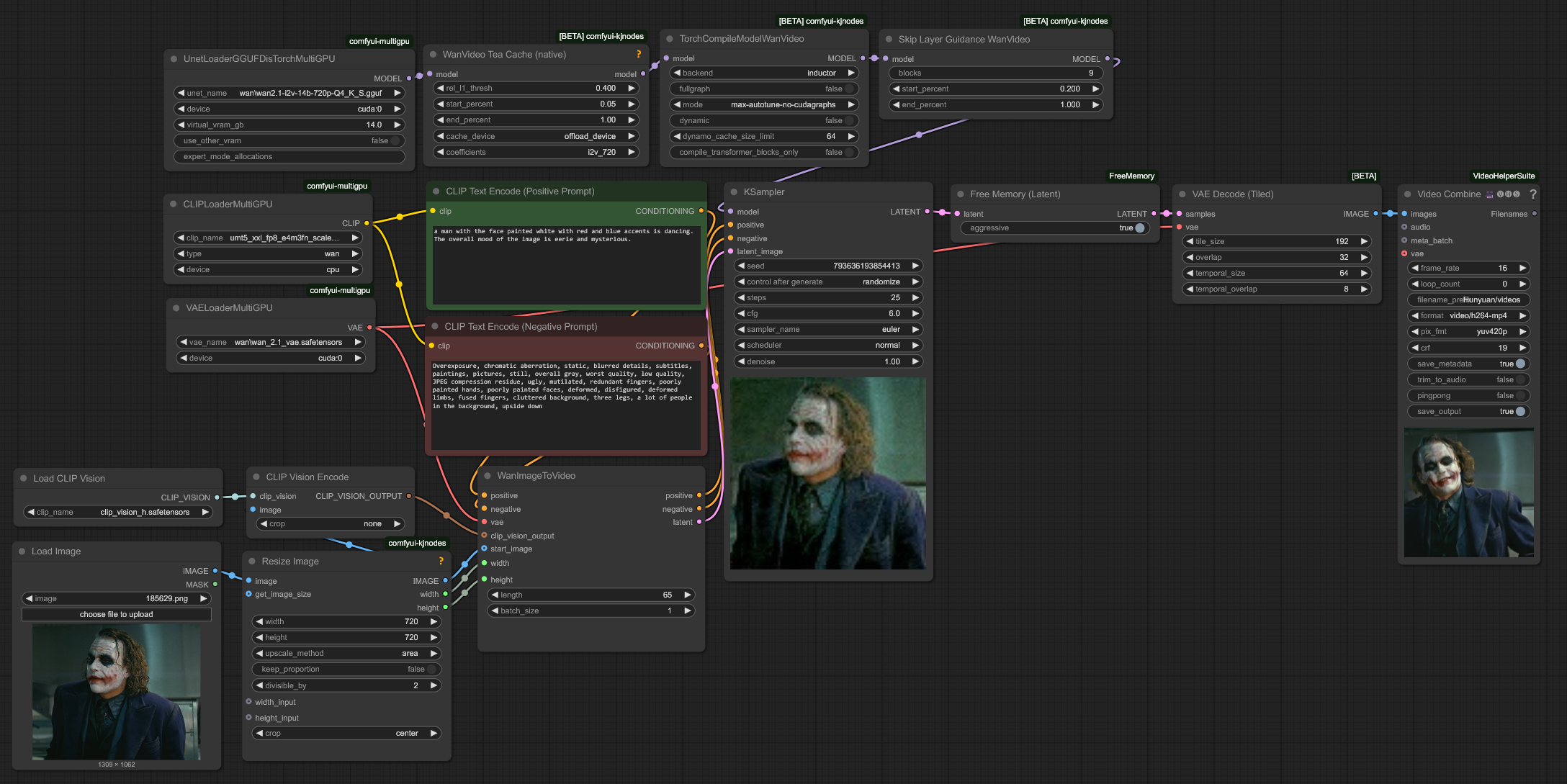
Pastebin : https://pastebin.com/P3C0xPU2
Important Note
If this is your first time using this workflow, set the length of the WanImageToVideo node to 1 and run it. From the second time on, you can set it to the desired length.
Custom Nodes
You have to install these cutoms Nodes :
MultiGPU
(UnetLoaderGGUFDisTorchMultiGPU, DualCLIPLoaderMultiGPU, VAELoaderMultiGPU)
these will enables offloading GGUF, CLIP, and VAE models to system RAM
Offloading models does not reduce generation time but allows for higher resolutions and longer video lengths by freeing VRAM
Avoid offloading the VAE to CPU, as it will drastically increase latent decoding time
KJNodes
(WanVideo Tea Cache (native),TorchCompileModelWanVideo, Skip Layer Guidance Wan Video)
WanVideo Tea Cache (native)
this will cut the generation time almost in half
With Wan 2.1 14B model, high threshold won't produce much noise
TorchCompileModelWanVideo
It will boost your generation time, make sure to set mode max-autotune-no-cudagraphs otherwise It will give you error
Skip Layer Guidance Wan Video
this will improve your video quality a lot, make sure to set block 9, not 10
FreeMemory
(Free Memory (Latent))
It will preventing VRAM Out-of-Memory (OOM) errors between the Sampler and Tiled VAE Decode nodes.
Make sure this node is connected and the aggressive setting is enabled.
VAE Decode
Make sure adjust tile size to below 256 or 192, or It will give you Vram OOM
WanImageToVideo
720 x 720px, 65 frames, 25 steps takes 11:00

- Attempting to render videos with more than 65 frames results in an exponential increase in processing time or mostly gives you OOM.
- When you are trying different step size, make sure Ksampler pass atleast 2 steps before initializing TeaCache, otherwise It will produce noisy mass.
- 20 steps size will take around 10:00 (total generation time is about 660 seconds), It will have some quality degradation. (Personally I won't recommend)